Explore possible futures (pyhton)
Commit and checkout
Presentation
This is the fifth tutorial! In the previous tutorial, we saw how to manage several instances of Ontologenius, each representing a specific agent. However, each of these instances represents only an agent's knowledge base at present. When planning, we may need to estimate a possible future state of a knowledge base to execute algorithms on it. Of course, one cannot simply modify the current knowledge base of an agent at the risk of breaking it and being disturbed by updates coming from the current situation. In this tutorial, we will see how to effectively manage estimated knowledge bases.
Since this process is very specific and must be used in global architecture, we will not do any mini-project which could be too complex to set up. We will simply create an executable that will generate several possible future states and try to understand together the best practices to do so.
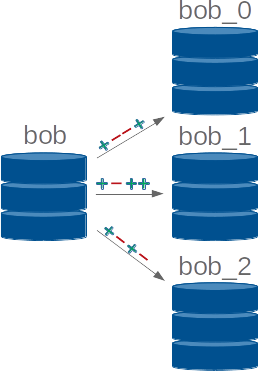 Based on what we saw in the previous tutorials, the only way to have instances for future knowledge base
estimates would be to ... create new instances. I hope you see how bad this solution is. When we create a
new instance, it loads the common ground but we don't want common ground but a copy of an actual instance.
Also, by proceeding like this, if we have specified an internal file, each of these instances will
be saved when it is killed, and depending on whether there is a backup of a previous execution or not, the
new instance will start with this previous file or with the common ground.
Based on what we saw in the previous tutorials, the only way to have instances for future knowledge base
estimates would be to ... create new instances. I hope you see how bad this solution is. When we create a
new instance, it loads the common ground but we don't want common ground but a copy of an actual instance.
Also, by proceeding like this, if we have specified an internal file, each of these instances will
be saved when it is killed, and depending on whether there is a backup of a previous execution or not, the
new instance will start with this previous file or with the common ground.
At this point, you should see that with such management it will be unmanageable. Fortunately, if we do a tutorial on it it is that we have a way to do better.
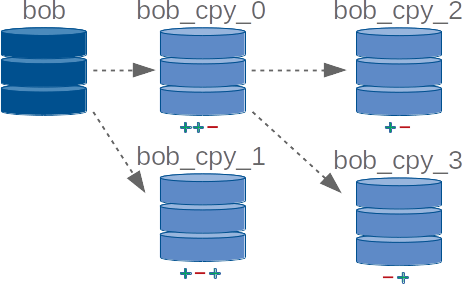
We have now solved the main problems identified above and we can also imagine interweaving as illustrated opposite to create two new states from one.
However, a deep copy is not a trivial process and it takes a little time to execute. Although this time can be negligible if we make only one copy, if we imagine a planning problem with a hundred states it can greatly affect the general performance of the planning all this for very often a low number of changes between each copy. Also, if you try to create a hundred Ontologenius instances, your computer will say "NO" at some point ... With my tests, I manage to create only 83 at the same time.
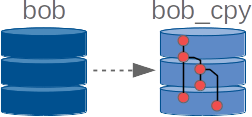 The second feature offered by Ontologenius is a kind of versioning system on copied instances. Much like git, you can
make changes to a copied instance and then commit those changes with a commit name. Then you can continue to make
changes or go to a specific commit using its name. With this feature, you can represent multiple states of a
knowledge base in a single instance.
The second feature offered by Ontologenius is a kind of versioning system on copied instances. Much like git, you can
make changes to a copied instance and then commit those changes with a commit name. Then you can continue to make
changes or go to a specific commit using its name. With this feature, you can represent multiple states of a
knowledge base in a single instance.
The ontology used
For this tutorial, we will not use existing ontology. We will create it dynamically to better observe the effects of our modifications.
Before you start
Before moving on, you can create a launch file. Leave the "files" argument empty and then set the "intern_file" argument to "futures.owl".
Let's call this file futures.launch and put it in our package in the folder launch.
Let's call this file futures.xml and put it in our package in the folder launch.
Let's call this file futures.py and put it in our package in the folder launch.
Let's call this file futures.yaml and put it in our package in the folder launch.
You can see here that we base our launch file on the file "ontologenius_multi" once again. Because we are going to create a separate instance of Ontologenius that will represent the knowledge base for future estimates, we must be able to manage multiple instances.
By specifying an internal file, Ontologenius is allowed to save the ontology it contains in a file when it is stopped and to reload it on its next start. We will see more precisely the effect of this internal file on our estimates.